 . The first
command is
. The first
command isThe examples in this section build on the examples described in the previous section. The first two examples introduce basic concepts about transformations, categorical variables, and missing values in EPICURE. In the second example the data are read. The final example in this section illustrates how transformations can be used after the data have been read. The complete script for these examples is shown in Listing 3.1.
These examples read the data from the tbfchrt.csv file used in
Example 3.1. If
you are going to continue the EPICURE session from previous examples, press
Reset script
toolbar button . The first
command is
USETXT ../exdata/tbfchrt.csv @
Example 3.4 Transformations before Input: Record Deletion, Missing Values, and IF Statements
The transformations specified following the first TRAN command are used to indicate that all records with brstat values equal to 2 are to be deleted as the data are read, to rescale (positive) dose values, and to create an exposure indicator (exposed). The statements used for these transformations are
TRAN IF brstat == 2 THEN DELETE ENDIF ;
IF dose > 0 THEN
dose = dose/100 ;
exposed = 1 ;
ELIF dose == 0 THEN
exposed = 0 ;
ELSE
exposed = %MV ; dose = %MV ;
ENDIF
@
This example illustrates the basic transformation syntax and demonstrates the use of the IF - ELSE - ELIF - THEN - ENDIF structure. Individual transformations, such as dose = dose/100, are delimited by semicolons. The ELSE and ELIF (else if) clauses are optional. Multiple statements (delimited by semicolons) may be used after THEN, ELSE or ELIF statements. The semicolons may be omitted from statements immediately preceding a THEN, ELSE, ELIF, or ENDIF statement. Nested IF's are not allowed.
DELETE is a special function that is used to omit selected records from the data set created by the program. The DELETE function has an effect when used in transformations specified before the data are read (which occurs when the INPUT command is given) but is ignored for transformations given after the data have been read. The transformation statement exposed = %MV illustrates the use of another special function. The %MV function, which has no arguments, simply returns the EPICURE missing value code.
These transformations could be specified in the import data dialogs accessed through the File/New Analysis menu.
Example 3.5 Transformations to Create Categorical Variables
The second set of transformations are coded as
TRAN aftcat = 1 + (aft >= 20) + (aft >= 30) +
(aft >= 40) ;
dcat = (dose > 0) + (dose >= 1) + (dose >= 3) ;
@
These statements create two new variables, aftcat and dcat. These transformations illustrate the use of logical comparisons in arithmetic expressions, which is an extremely useful feature of the EPICURE transformation language. A logical comparison such as afe>= 20 is equal to 1 when the statement is true and 0 when it is false. The four afe categories defined in this example are 0 -19 (category 1), 20 -29 (category 2), 30 -39 (category 3), and 40 or over (category 4). Similarly, four dose categories are defined: zero dose, less than 1, less than 2, and 3 or more. These categories are coded as 0, 1, 2, and 3, respectively. Since negative values of dose were recoded as missing, the dcat variable will be coded as missing for those records with missing dose values.
For an integer-valued variable to be recognized as a categorical variable in EPICURE analyses, it is necessary to use the LEVELS command to indicate which variables are categorical. Since in this example the data have not yet been read, it is also necessary to specify the category codes explicitly. (This is not necessary after the data have been read, because the programs can then determine the number of levels and range directly from the data.) This can be done with the command
LEVELS aftcat 4 dcat 0:3 @
When a single number, 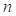 , is given after the variable name, it
is assumed that the variable is coded with values from 1 to . If this is not the case, you must
specify both the lower and upper bounds as illustrated with the dcat
example.
, is given after the variable name, it
is assumed that the variable is coded with values from 1 to . If this is not the case, you must
specify both the lower and upper bounds as illustrated with the dcat
example.
Example 3.6 Reading the Data -The INPUT Command
The next command,
INPUT @
is used to begin processing of the input CSV file. The transformations described previously will be carried out as the data are read. Once the file has been read, a message will be written describing the number of records read, the number of records kept in the working file, and the number rejected in user edits. Covariate names can be displayed using SHOW command. However, this information can be found in the upper left window of the EPICURE. The output written to the screen and log file following this command is shown below.
Output 3.4 Summary output for Example 3.4 - Example 3.6
INPUT @
Input from ../exdata/tbfchrt.csv
1761 records read 1758 records used
3 records rejected
23 variables defined At least 500 additional variables can be created.
SHOW@
The current variables are:
|
id |
hosp |
byr |
bmo |
bdy |
inyr |
inmo |
indy |
tryr |
|
trmo |
trdy |
dose |
numbtf |
aft |
dxyr |
dxmo |
dxdy |
brstat |
|
%ORD |
%SEL |
exposed |
aftcat |
dcat |
|
|
|
|
23 variables used. At least 500 additional variables can be created.
The current constants are:
%MV
1 constants used
Example 3.7 Transformations after Input: Missing Value Recodes and Categorical Variable Specification
The next command,
MISS numbtf > 990 @
instructs the program to recode numbtf to the internal missing value code whenever numbtf is greater than 990.
Although it is possible to recode the internal missing value code to valid numeric values, it is not, in general, possible to recreate the original values. As many as five missing value codes or conditions can be given for a single variable with the MISS command. If more than five missing values codes are to be specified for a variable, additional MISS commands may be used. It is generally easier to use the MISS command to define missing values than to use transformations; however, the MISS command can only be used once the data have been read.
The next several statements specify additional transformations:
TRAN IF ISMISS(dose) THEN
expcat = 2 ;
dcat = %MV ;
ELSE
expcat = (dose > 0) ;
ENDIF
bcohort = 1 + (byr >= 1910) + (byr >= 1920) ;
ldose = log(dose) ;
@
Since the data have been read and stored in the program workspace, these transformations are carried out as soon as the @ is read. The first set of transformation statements are used to create a categorical exposure variable that has the value 0 when dose is 0, 1 when dose is greater than 0, and 2 when dose is missing. Because we added an additional missing value code for dose, the value of dcat is also recoded if dose is missing. The ISMISS function used in this example returns the value 1 if the argument is missing and 0 if it is not missing. The final two transformations create an additional integer-valued variable (expcat), which will subsequently be declared categorical, and a log dose variable (ldose). The EPICURE LOG function computes natural logarithms (base e). Base 10 logs can be obtained by dividing the natural log by log(10).
The data contains more than 700 records in which the dose is 0. The value of log dose is not defined for 0 so the value of ldose is set as missing and the log file indicates how many times this occurred with the following message:
*** Transformation warnings ***
Log of zero occurred 706 times
The next command
LEVELS bcohort expcat @
indicates that the listed variables are to be treated as categorical variables in analyses. Categorical variables must be coded as non-negative integers. Once the data have been read, the program can determine the number of levels and origin automatically. However, it is possible and sometimes necessary to specify both the number of levels and origin explicitly as illustrated in the tabulation mode example in Making Tables with DATAB. As subsequent examples show, categorical variables are useful in making tables, in computing summary statistics, and in modeling.